Knowledge Graphs (KGs) have gained attention due to their ability to represent structured and interlinked information. KGs represent knowledge in the form of relations between entities, referred to as facts, typically grounded in formal ontological models. Such machine-readable formats enable AI systems to make decisions using clear and verifiable data. Consequently, KGs have become essential […]
Laboratory for Natural Speech and Language processing
LIVE Quantum – Development of an Integrated AI Platform for Multichannel Personalized Management of User Requests
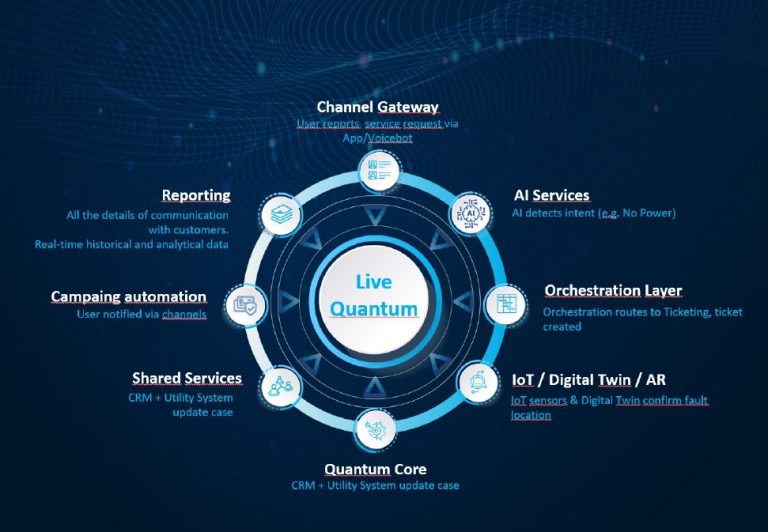
The LIVE Quantum project focuses on the research and development of an advanced, integrated AI-based platform for multichannel, personalized management of user requests, primarily targeting operators of critical infrastructure systems such as energy, water, gas, telecommunications, and utilities. The project combines industrial research and experimental development activities to create a scalable and modular solution that […]
Pretraining and evaluation of BERT models for climate research
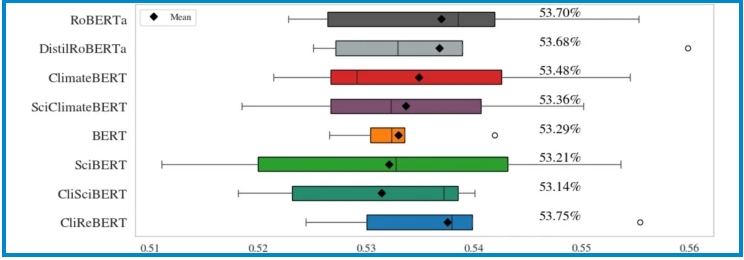
Motivated by the pressing issue of climate change and the growing volume of data, we pretrain three new language models using climate change research papers published in top-tier journals. Adaptation of existing domain-specific models based on Bidirectional Encoder Representations from Transformers (BERT) architecture is utilized for CliSciBERT (domain adaptation of SciBERT) and SciClimateBERT (domain adaptation […]
Recursively Autoregressive Autoencoder for Pyramidal Text Representation
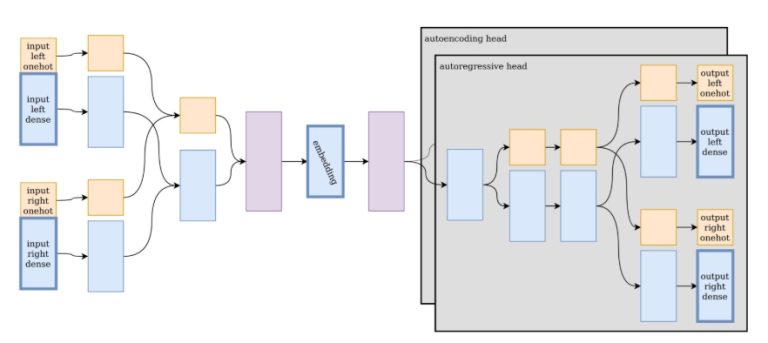
We introduce Pyramidal Recursive learning (PyRv), a novel method for text representationlearning. This approach constructs a pyramidal hierarchy by recursively building representations of phrases, starting from tokens (characters, subwords, or words). At each level, N representations are recursively combined, resulting in N-1 representations on the level above, abstracting the input text from characters or subwords […]
Retweet Prediction Based on Heterogeneous Data Sources: The Combination of Text and Multilayer Network Features
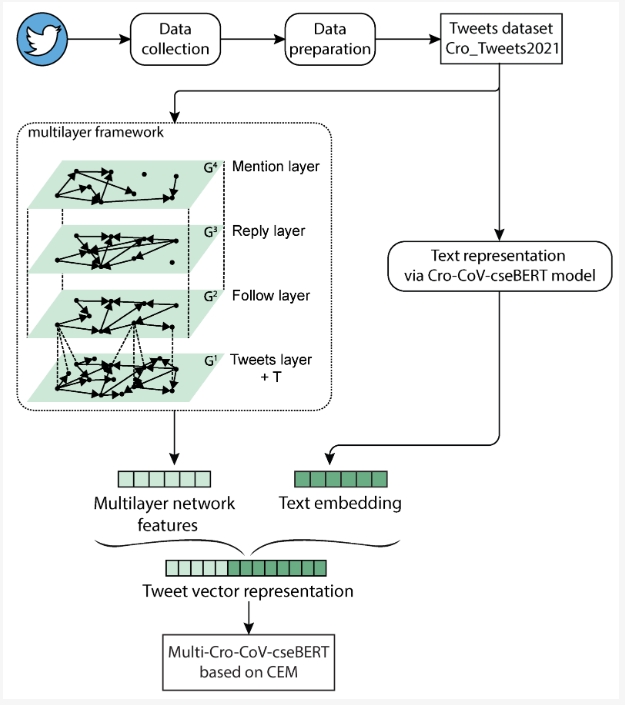
Retweet prediction is an important task in the context of various problems, such as information spreading analysis, automatic fake news detection, social media monitoring, etc. In this study, we explore retweet prediction based on heterogeneous data sources. In order to classify a tweet according to the number of retweets, we combine features extracted from the […]
Neural Natural Language Generation: A Survey on Multilinguality, Multimodality, Controllability and Learning
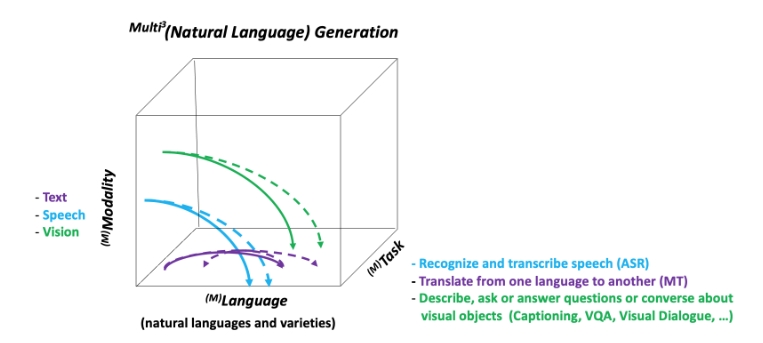
Developing artificial learning systems that can understand and generate natural language has been one of the long-standing goals of artificial intelligence. Recent decades have witnessed an impressive progress on both of these problems, giving rise to a new family of approaches. Especially, the advances in deep learning over the past couple of years have led […]
Characterisation of COVID-19-Related Tweets in the Croatian Language: Framework Based on the Cro-CoV-cseBERT Model
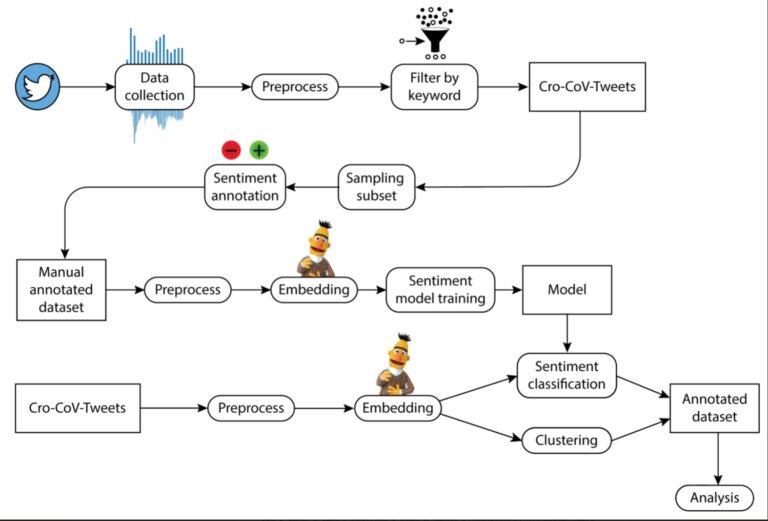
This study aims to provide insights into the COVID-19-related communication on Twitter in the Republic of Croatia. For that purpose, we developed an NL-based framework that enables automatic analysis of a large dataset of tweets in the Croatian language. We collected and analysed 206,196 tweets related to COVID-19 and constructed a dataset of 10,000 tweets […]
Infoveillance of the Croatian Online Media during the COVID-19 Pandemic: a One-Year Longitudinal NLP Study
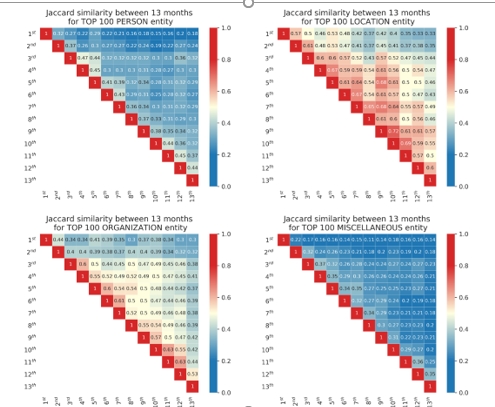
Background: Online media plays an important role in public health emergencies and serves as a communication platform. Infoveillance of online media during the COVID-19 pandemic is an important step toward a better understanding of crisis communication. Objective: The goal of this study is to perform a longitudinal analysis of the COVID-19 related content based on natural language […]
Predicting Seagoing Ship Energy Efficiency from the Operational Data
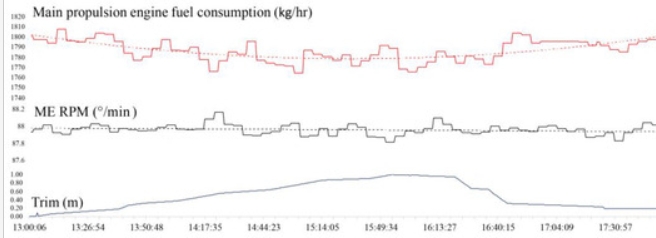
This paper presents the application of machine learning (ML) methods in setting up a model with the aim of predicting the energy efficiency of seagoing ships in the case of a vessel for the transport of liquefied petroleum gas (LPG). The ML algorithm is learned from shipboard automation system measurement data, noon logbook reports, and […]
A Comparison of Approaches for Measuring the Semantic Similarity of Short Texts Based on Word Embeddings
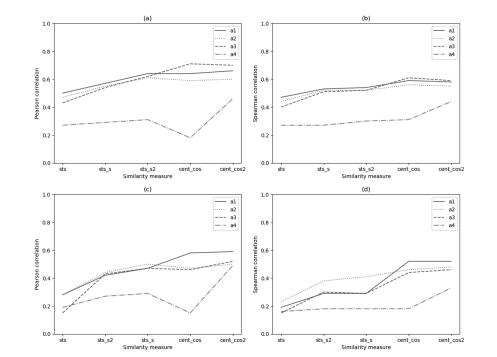
Measuring the semantic similarity of texts has a vital role in various tasks from the field of natural language processing. In this paper, we describe a set of experiments we carried out to evaluate and compare the performance of different approaches for measuring the semantic similarity of short texts. We perform a comparison of four […]
