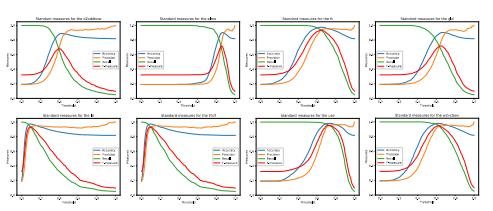
Paraphrase detection is important for a number of applications, including plagiarism detection, authorship attribution, question answering, text summarization, text mining in general, etc. In this paper, we give a performance overview of various types of corpus-based models, especially deep learning (DL) models, with the task of paraphrase detection. We report the results of eight models (LSI, TF-IDF, Word2Vec, Doc2Vec, GloVe, FastText, ELMO, and USE) evaluated on three different public available corpora: Microsoft Research Paraphrase Corpus, Clough and Stevenson and Webis Crowd Paraphrase Corpus 2011. Through a great number of experiments, we decided on the most appropriate approaches for text pre-processing: hyper-parameters, sub-model selection—where they exist (e.g., Skipgram vs. CBOW), distance measures, and semantic similarity/paraphrase detection threshold. Our findings and those of other researchers who have used deep learning models show that DL models are very competitive with traditional state-of-the-art approaches and have potential that should be further developed.
