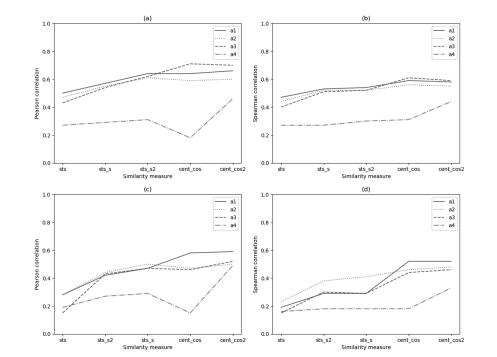
Measuring the semantic similarity of texts has a vital role in various tasks from the field of natural language processing. In this paper, we describe a set of experiments we carried out to evaluate and compare the performance of different approaches for measuring the semantic similarity of short texts. We perform a comparison of four models based on word embeddings: two variants of Word2Vec (one based on Word2Vec trained on a specific dataset and the second extending it with embeddings of word senses), FastText, and TF-IDF. Since these models provide word vectors, we experiment with various methods that calculate the semantic similarity of short texts based on word vectors. More precisely, for each of these models, we test five methods for aggregating word embeddings into text embedding. We introduced three methods by making variations of two commonly used similarity measures. One method is an extension of the cosine similarity based on centroids, and the other two methods are variations of the Okapi BM25 function. We evaluate all approaches on the two publicly available datasets: SICK and Lee in terms of the Pearson and Spearman correlation. The results indicate that extended methods perform better from the original in most of the cases.
