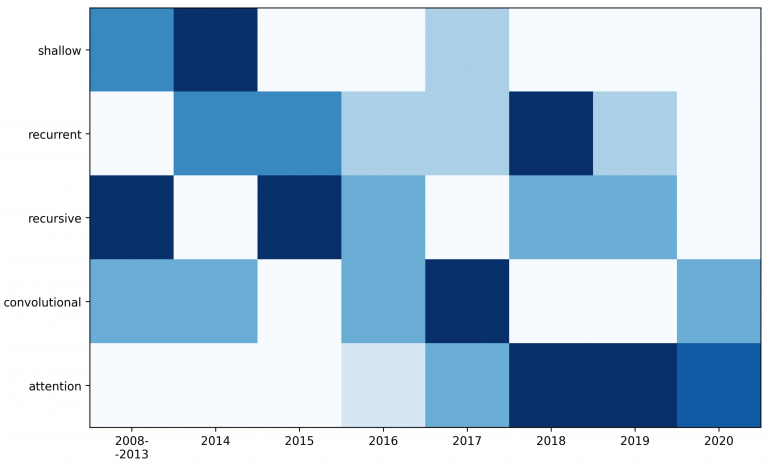
In natural language processing, text needs to be transformed into a machine-readable representation before any processing. The quality of further natural language processing tasks greatly depends on the quality of those representations. In this survey, we systematize and analyze 50 neural models from the last decade. The models described are grouped by the architecture of neural networks as shallow, recurrent, recursive, convolutional, and attention models. Furthermore, we categorize these models by representation level, input level, model type, and model supervision. We focus on task-independent representation models, discuss their advantages and drawbacks, and subsequently identify the promising directions for future neural text representation models. We describe the evaluation datasets and tasks used in the papers that introduced the models and compare the models based on relevant evaluations. The quality of a representation model can be evaluated as its capability to generalize to multiple unrelated tasks. Benchmark standardization is visible amongst recent models and the number of different tasks models are evaluated on is increasing.
