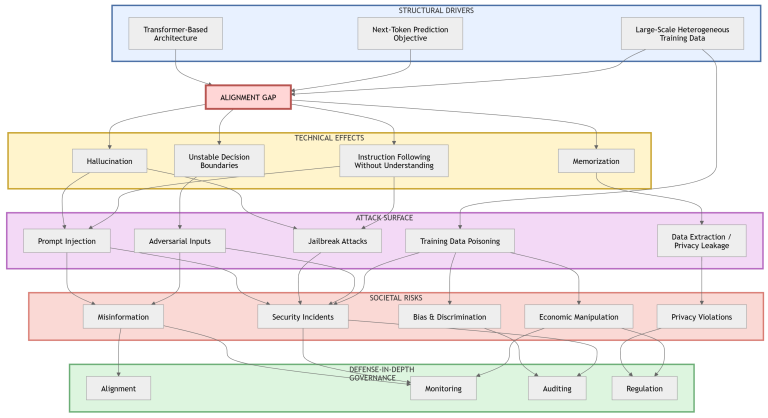
Large Language Models (LLMs) are increasingly deployed across professional and societal domains, introducing security, privacy, and governance challenges beyond traditional software vulnerabilities. Despite extensive research on individual risk categories, a unified lifecycle-oriented perspective connecting architectural properties, adversarial threats, and governance implications remains limited. This review examines security and privacy risks associated with LLMs through a lifecycle framework covering data acquisition, model training, alignment procedures, deployment, and post-deployment interaction. The study synthesizes prior research to construct a taxonomy of threats including prompt injection, jailbreaking, adversarial manipulation, training-stage attacks, privacy leakage, and socio-technical misuse. Ethical issues such as hallucination, bias amplification, and malicious use are analyzed alongside governance and regulatory frameworks. Results indicate that vulnerabilities in LLM systems arise primarily from probabilistic generation mechanisms, large-scale data ingestion, and complex deployment ecosystems rather than isolated implementation defects. Classical software vulnerability models therefore provide only partial coverage of risks associated with generative AI systems. The review is grounded in the concept of the alignment gap to explain how discrepancies between training objectives and real-world interaction contribute to persistent vulnerabilities. The findings highlight the need for lifecycle-oriented defense-in-depth strategies combining technical safeguards, privacy-preserving training, runtime monitoring, and governance mechanisms to support responsible deployment of LLM-based systems.
