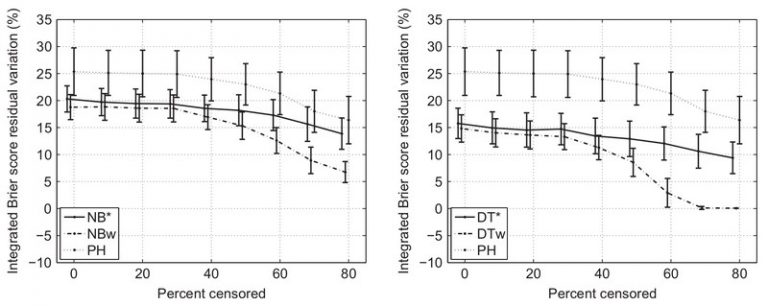
Various machine learning techniques have been applied to different problems in survival analysis in the last decade. They were usually adapted to learning from censored survival data by using the information on observation time. This includes learning from parts of the data or interventions to the learning algorithms. Efficient models were established in various fields of clinical medicine and bioinformatics. In this paper, we propose a pre-processing method for adapting the censored survival data to be used with ordinary machine learning algorithms. This is done by pre-assigning censored instances a positive or negative outcome according to their features and observation time. The proposed procedure calculates the goodness of fit of each censored instance to both the distribution of positives and the spoiled distribution of negatives in the entire dataset and relabels that instance accordingly. We performed a thorough empirical testing of our method in a simulation study and on two real-world medical datasets, using the naive Bayes classifier and decision trees. When compared to one of the popular ML methods dealing with survival, our method provided good results, especially when applied to heavily censored data.
