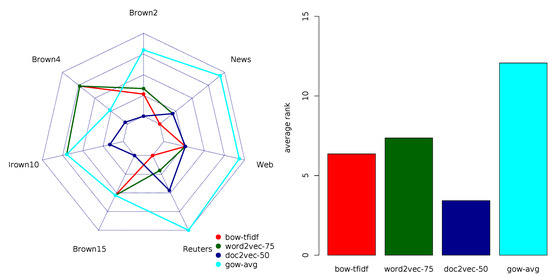
In this paper we perform a comparative analysis of three models for a feature representation of text documents in the context of document classification. In particular, we consider the most often used family of bag-of-words models, the recently proposed continuous space models word2vec and doc2vec, and the model based on the representation of text documents as language networks. While the bag-of-word models have been extensively used for the document classification task, the performance of the other two models for the same task have not been well understood. This is especially true for the network-based models that have been rarely considered for the representation of text documents for classification. In this study, we measure the performance of the document classifiers trained using the method of random forests for features generated with the three models and their variants. Multi-objective rankings are proposed as the framework for multi-criteria comparative analysis of the results. Finally, the results of the empirical comparison show that the commonly used bag-of-words model has a performance comparable to the one obtained by the emerging continuous-space model of doc2vec. In particular, the low-dimensional variants of doc2vec generating up to 75 features are among the top-performing document representation models. The results finally point out that doc2vec shows a superior performance in the tasks of classifying large documents.
