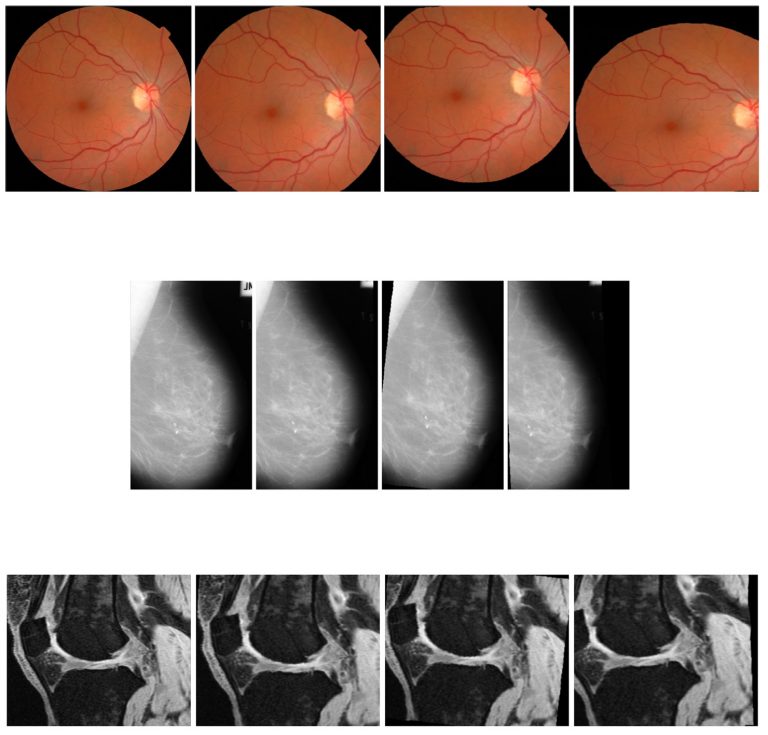
Following an obvious growth of available collections of medical images in recent years, both in number and in size, machine learning has nowadays become an important tool for solving various image-analysis-related problems, such as organ segmentation or injury/pathology detection. The potential of learning algorithms to produce models having good generalisation properties is highly dependent on model complexity and the amount of available data. Bearing in mind that complex concepts require the use of complex models, it is of paramount importance to mitigate representation complexity, where possible, therefore enabling the utilisation of simpler models for performing the same task. When dealing with image collections of quasi-symmetric organs, or imaging observations of organs taken from different quasi-symmetric perspectives, one way of reducing representation complexity would be aligning all the images in a collection for left-right or front-rear orientation. That way, a learning algorithm would not be dealing with learning redundant symmetric representations. In this paper, we study in detail the influence of such within-class variation on model complexity, and present a possible solution, that can be applied to medical-imaging computer-aided diagnosis systems. The proposed method involves compacting the data, extracting features and then learning to separate the mirror-image representation classes from one another. Two efficient approaches are considered for performing such orientation separation: a fully automated unsupervised approach and a semi-automated supervised approach. Both solutions are directly applicable to imaging data. Method performance is illustrated on two 2D and one 3D real-world publicly-available medical datasets, concerning different parts of human anatomy, and observed using different imaging techniques: colour fundus photography, mammography CT scans and volumetric knee-joint MR scans. Experimental results suggest that efficient organ-mirroring orientation-classifier models, having expected classification accuracy greater than 99%, can be estimated using either the unsupervised or the supervised approach. In the presence of noise, however, an equally good performance can be achieved only by using the supervised approach, learning from a small subset of labelled data.
The research was conducted at the Faculty of Engineering, University of Rijeka (www.riteh.uniri.hr).
