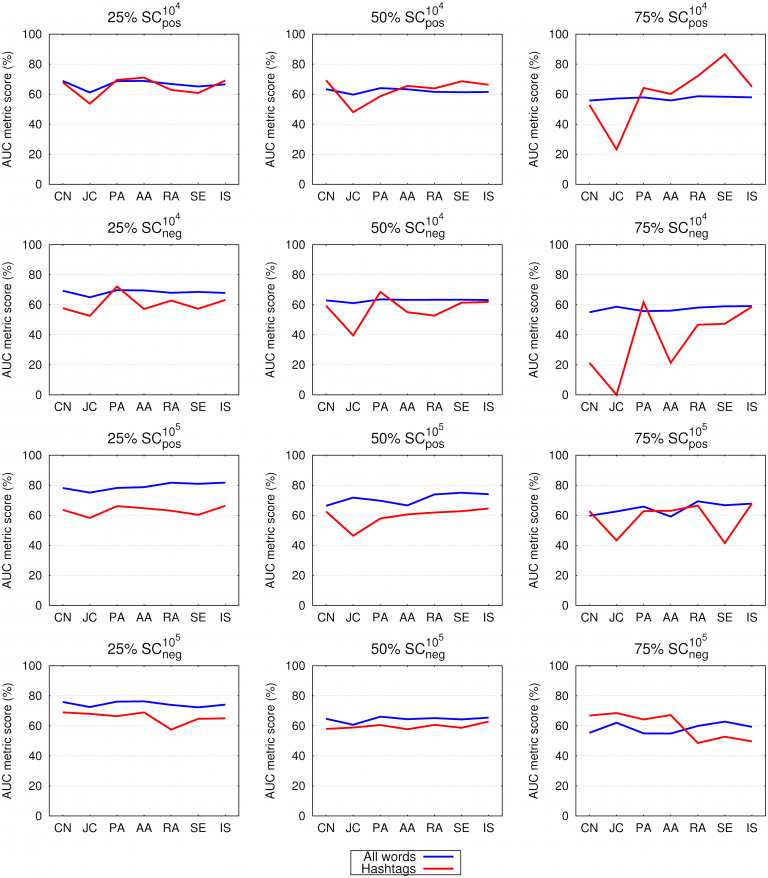
With over 300 million active users, Twitter is among the largest online news and social networking services in existence today. Open access to information on Twitter makes it a valuable source of data for research on social interactions, sentiment analysis, content diffusion, link prediction, and the dynamics behind human collective behaviour in general. Here we use Twitter data to construct co-occurrence language networks based on hashtags and based on all the words in tweets, and we use these networks to study link prediction by means of different methods and evaluation metrics. In addition to using five known methods, we propose two effective weighted similarity measures, and we compare the obtained outcomes in dependence on the selected semantic context of topics on Twitter. We find that hashtag networks yield to a large degree equal results as all-word networks, thus supporting the claim that hashtags alone robustly capture the semantic context of tweets, and as such are useful and suitable for studying the content and categorization. We also introduce ranking diagrams as an efficient tool for the comparison of the performance of different link prediction algorithms across multiple datasets. Our research indicates that successful link prediction algorithms work well in correctly foretelling highly probable links even if the information about a network structure is incomplete, and they do so even if the semantic context is rationalized to hashtags.
