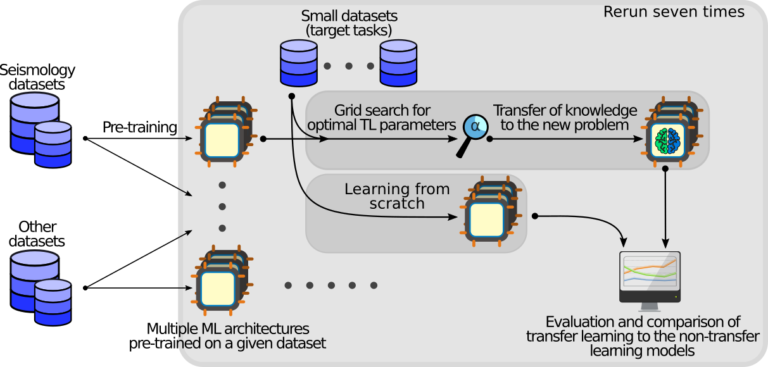
In practice, it is very challenging and sometimes impossible to collect datasets of labelled data large enough to successfully train a machine learning model, and one possible solution to this problem is using transfer learning. In this study, we investigate how transferable are features between different domains of time series data and under what conditions. The effects of transfer learning are observed in terms of the predictive performance of the models and their convergence rate during training. In our experiment, we used reduced datasets of 1500 and 9000 data instances to mimic real-world conditions. We trained two sets of models (four different architectures) on the reduced datasets: those trained with transfer learning and those trained from scratch. Knowledge transfer was performed both within the same application domain (seismology) and between different application domains (seismology, speech, medicine, finance). We observed the prediction performance of the models and their training convergence rate. We repeated the experiments seven times and applied statistical tests to confirm the validity of the results. The overall conclusion of our study is that transfer learning is highly likely to either increase or not negatively affect the model’s predictive performance or its training convergence rate. We discuss which source and target domains are compatible for knowledge transfer. We also discuss the effect of the target dataset size and the choice of the model and its hyperparameters on transfer learning.
