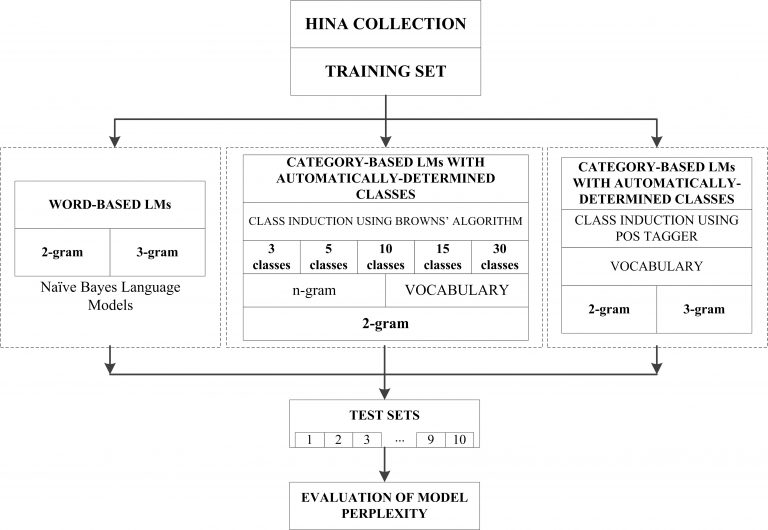
Statistical language modeling involves techniques and procedures that assign probabilities to word sequences or, said in other words, estimate the regularity of the language. This paper presents basic characteristics of statistical language models, reviews their use in the large set of speech and language applications, explains their formal definition and shows different types of language models. Detailed overview of n-gram and class-based models (as well as their combinations) is given chronologically, by type and complexity of models, and in aspect of their use in different NLP applications for different natural languages. The proposed experimental procedure compares three different types of statistical language models: n-gram models based on words, categorical models based on automatically determined categories and categorical models based on POS tags. In the paper, we propose a language model for contemporary Croatian texts, a procedure how to determine the best n-gram and the optimal number of categories, which leads to significant decrease of language model perplexity, estimated from the Croatian News Agency articles (HINA) corpus. Using different language models estimated from the HINA corpus, we show experimentally that models based on categories contribute to a better description of the natural language than those based on words. These findings of the proposed experiment are applicable, except for Croatian, for similar highly inflectional languages with rich morphology and non-mandatory sentence word order.
