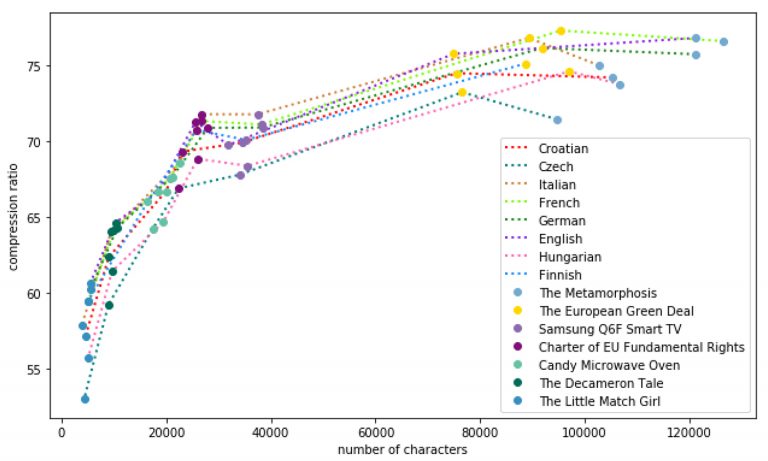
The rapid growth in the amount of data in the digital world leads to the need for data compression, and so forth, reducing the number of bits needed to represent a text file, an image, audio, or video content. Compressing data saves storage capacity and speeds up data transmission. In this paper, we focus on the text compression and provide a comparison of algorithms (in particular, entropy-based arithmetic and dictionary-based Lempel–Ziv–Welch (LZW) methods) for text compression in different languages (Croatian, Finnish, Hungarian, Czech, Italian, French, German, and English). The main goal is to answer a question: ”How does the language of a text affect the compression ratio?” The results indicated that the compression ratio is affected by the size of the language alphabet, and size or type of the text. For example, The European Green Deal was compressed by 75.79%, 76.17%, 77.33%, 76.84%, 73.25%, 74.63%, 75.14%, and 74.51% using the LZW algorithm, and by 72.54%, 71.47%, 72.87%, 73.43%, 69.62%, 69.94%, 72.42% and 72% using the arithmetic algorithm for the English, German, French, Italian, Czech, Hungarian, Finnish, and Croatian versions, respectively.
