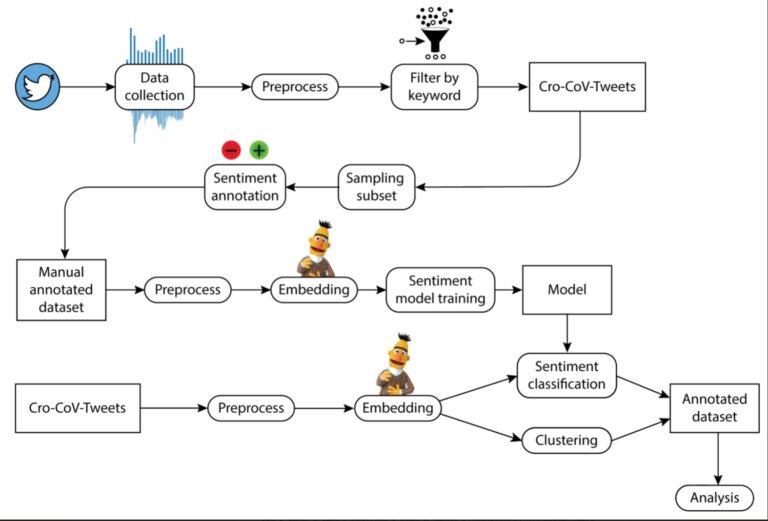
This study aims to provide insights into the COVID-19-related communication on Twitter in the Republic of Croatia. For that purpose, we developed an NL-based framework that enables automatic analysis of a large dataset of tweets in the Croatian language. We collected and analysed 206,196 tweets related to COVID-19 and constructed a dataset of 10,000 tweets which we manually annotated with a sentiment label. We trained the Cro-CoV-cseBERT language model for the representation and clustering of tweets. Additionally, we compared the performance of four machine learning algorithms on the task of sentiment classification. After identifying the best performing setup of NLP methods, we applied the proposed framework in the task of characterisation of COVID-19 tweets in Croatia. More precisely, we performed sentiment analysis and tracked the sentiment over time. Furthermore, we detected how tweets are grouped into clusters with similar themes across three pandemic waves. Additionally, we characterised the tweets by analysing the distribution of sentiment polarity (in each thematic cluster and over time) and the number of retweets (in each thematic cluster and sentiment class). These results could be useful for additional research and interpretation in the domains of sociology, psychology or other sciences, as well as for the authorities, who could use them to address crisis communication problems.
