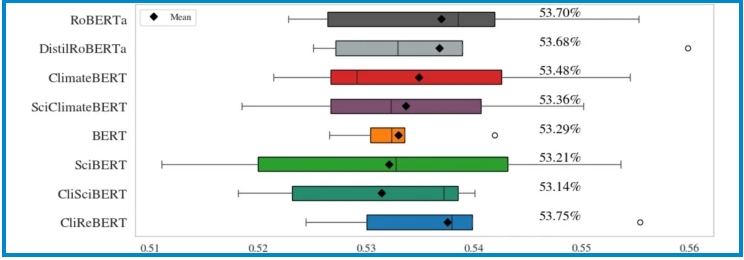
Motivated by the pressing issue of climate change and the growing volume of data, we pretrain three new language models using climate change research papers published in top-tier journals. Adaptation of existing domain-specific models based on Bidirectional Encoder Representations from Transformers (BERT) architecture is utilized for CliSciBERT (domain adaptation of SciBERT) and SciClimateBERT (domain adaptation of ClimateBERT) and pretraining from scratch resulted in CliReBERT (Climate Research BERT). The performance assessment is performed on the climate change NLP text classification benchmark ClimaBench. We evaluate SciBERT, ClimateBERT, BERT, RoBERTa and DistilRoBERTa – along with our new models – CliReBERT, CliSciBERT and SciClimateBERT – using five different random seeds on all seven ClimaBench datasets. CliReBERT achieves the highest overall performance with a macro-averaged F1 score of 65.45%, and performs better than other models on three out of seven tasks. Additionally, CliReBERT demonstrates the most stable fine-tuning behavior, yielding the lowest average standard deviation across seeds (0.0118). The 5-fold stratified cross-validation on the SciDCC dataset showed that CliReBERT achieved the highest overall macro-average F1 score (53.75%), performing slightly better than RoBERTa and DistilRoBERTa, while the domain-adapted models underperformed their base counterparts. The results show the usefulness of the new pretrained models for text classification in the climate change domain and underline the positive influence of domain-specific vocabulary.
